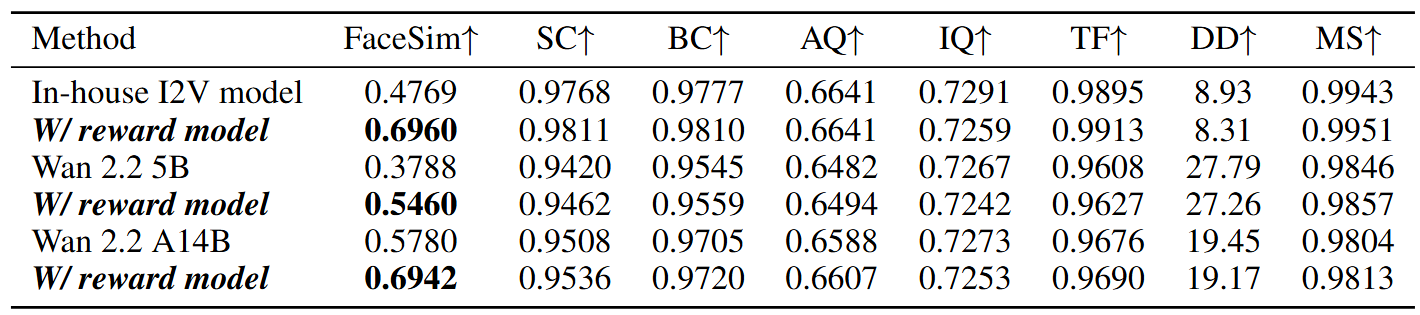
Method
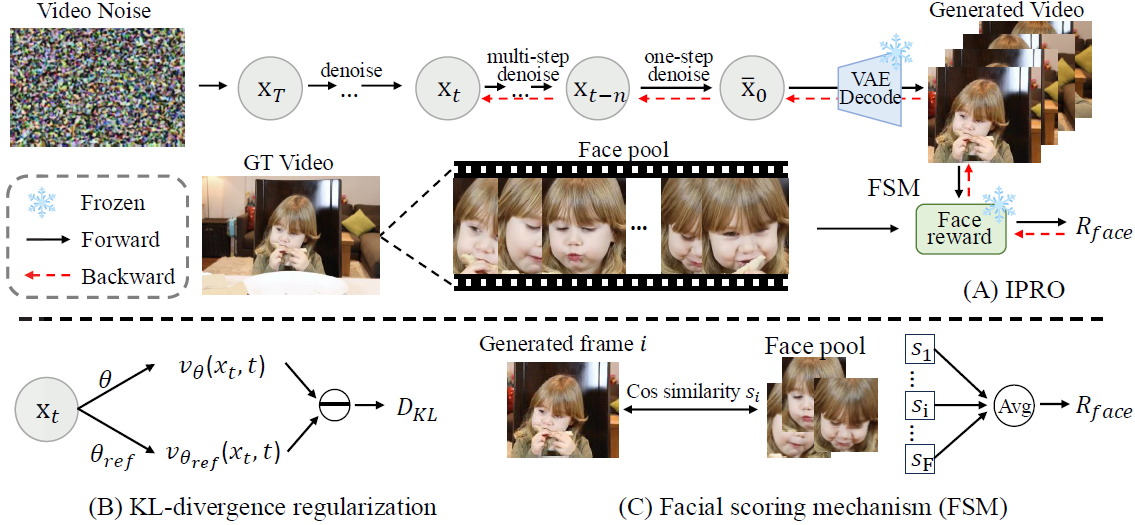
Overview of our method. (A) IPRO predicts \(\bar{x}_0\) from the noise input \(x_T\) , and the prediction is visualized through a frozen VAE decoder and scored by a face reward model with our facial scoring mechanism (C). This reward signal is used to update the trainable parts of the model, thereby steering the generation process to produce videos with consistent identity. (B) We further incorporate a KL-divergence regularization to alleviate reward hacking.